هوش تجاری
الگوریتمهای رگرسیون و طبقهبندی چه تفاوتی با هم دارند؟
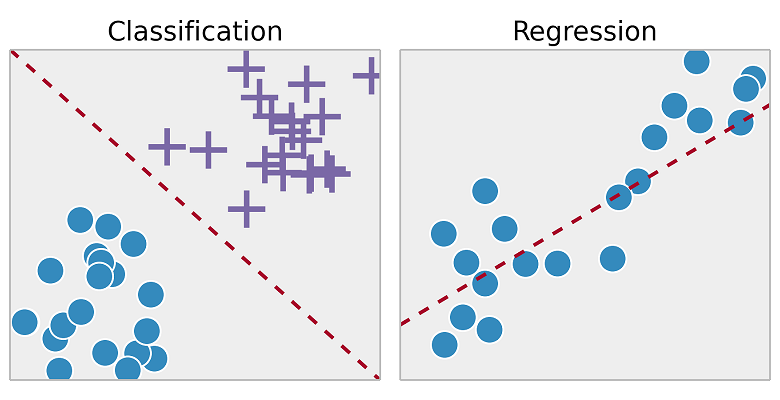
در تجزیه و تحلیل دادهها، مدلهای رگرسیون (Regression) و طبقهبندی (Classification) برای بررسی دادهها و پیشبینی امور استفاده میشوند. به بیان دیگر، برای هر تحلیلگر داده، مهارت آماری یک امر ضروری است. یکی از زمینههایی که این مهارتها به ویژه مفید واقع میشوند، حوزه تجزیه و تحلیل پیشگویانه (Predictive Analytics) است.
مناطق نوظهور مانند یادگیری ماشین و هوش مصنوعی برای شناسایی الگوها و پیشبینی روندها به تجزیه و تحلیل پیشگویانه، متکی هستند. دو الگوریتم رایج که برای حل این نوع مشکلات استفاده میشوند نیز الگوریتمهای رگرسیون و طبقهبندی خواهند بود.
با این حال، هر کدام متناسب با انواع مختلف داده، وظایف پیشبینی را بر عهده دارند. اگر شما علاقهمند به یادگیری ماشین و هوش مصنوعی هستید، باید یاد بگیرید که تفاوت بین طبقهبندی و مشکلات رگرسیون را تشخیص دهید. اما این مدلها چگونه کار میکنند و چه تفاوتی با هم دارند؟
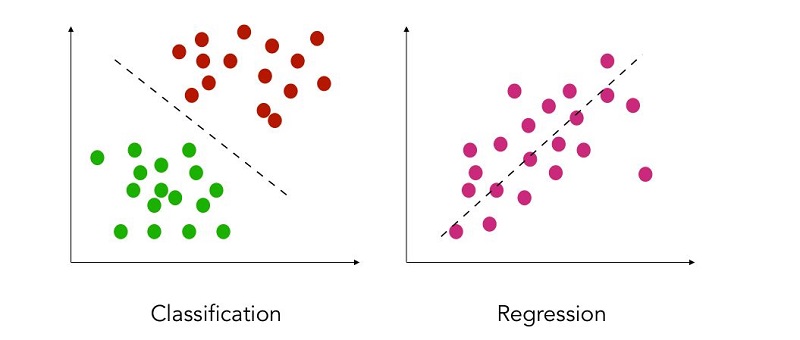
در این مقاله، ما رگرسیون و طبقهبندی را با جزئیات بیشتری، از جمله نحوه استفاده از آنها برای مدلسازی تحلیل پیشگویانه را بررسی خواهیم کرد. تا دریابیم که:
- تجزیه و تحلیل پیشگویانه چیست؟
- طبقهبندی چیست؟
- رگرسیون چیست؟
- طبقهبندی در مقابل رگرسیون: تفاوت چیست؟
همانطور که مشاهده میکنید، برای بسط این موضوع، ابتدا تجزیه و تحلیلهای پیشگویانه را تعریف خواهیم کرد.
تحلیل پیشگویانه چیست؟
تجزیه و تحلیل پیشگویانه یا Predictive Analytics، قسمتی از تجزیه و تحلیل دادهها است که از اطلاعات موجود برای پیشبینی روندها یا رفتارهای آینده استفاده میکند. این نوع تحلیل در بسیاری از زمینههای تجزیه و تحلیل دادهها اعمال میشود، اما به ویژه در زمینههای نوظهور هوش مصنوعی و یادگیری ماشین بسیار برجسته است.
در حالی که روشهای مختلفی برای انجام تحلیل پیشگویانه وجود دارد، همه مدلهای پیشبینی دارای ویژگیهای خاصی هستند. برای شروع بهتر است بدانیم، همه آنها به متغیرهای ورودی مستقل (یا “توضیحی”) متکی هستند. سپس از این متغیرهای ورودی برای استنباط یا پیشبینی نتیجه ناشناخته (معروف به متغیر خروجی وابسته) استفاده میشود.
البته، هنگامی که کار شما تلاش و پیشبینی است، مهم است که تا حد ممکن، دقیق باشید. دقت تحلیل پیشگویانه به عوامل مختلفی بستگی دارد. در مرحله اول، تجزیه و تحلیل پیشگویانه اغلب از مجموعه دادههای مربوط به “آموزش” استفاده میکند. این مجموعه دادهها به راهنمایی الگوریتمی با الگوهای موجود که صحیح شناخته شدهاند، کمک میکند.

به بیان دیگر به طور طبیعی، کیفیت این مجموعه دادهها بر نتیجه تأثیر میگذارد. عمق تجزیه و تحلیل و پیش فرضهای ارائه شده هنگام برنامهنویسی الگوریتم از دیگر عوامل موثر بر دقت در این امر است. جای تعجب نیست که سطح تجربه تحلیلگر داده، در حل مسئله نیز یک عامل تعیینکننده کلیدی است.
همانطور که ممکن است شما هم به آن فکر کرده باشید، تحلیل پیشگویانه همیشه ساده نیست. با این حال، این مسئله پتانسیل بسیار قدرتمندی دارد. به عنوان مثال، در املاک و مستغلات، از تحلیل پیشگویانه برای تخمین قیمت خانههای آینده استفاده میشود. ساختار ایمیل شما، برای تعیین هرزنامه بودن یا نبودن ایمیلهای دریافتی، از تجزیه و تحلیل پیشگویانه استفاده میکند. تجزیه و تحلیل پیشگویانه همچنین در هواشناسی برای پیشبینی آب و هوا، بهبود استراتژیهای فروش در بخشهایی مانند خردهفروشی و حتی برای تشخیص سرطان استفاده میشود. موارد استفاده از این روش، تقریبا بیپایان هستند.
آنچه تاکنون توصیف کردیم مفهوم کلی تجزیه و تحلیل پیشگویانه است. فراتر از این، هر نوع کار برای حل آنها به ابزارها یا مدلهای مختلفی نیاز دارد. اینجاست که الگوریتمها وارد عمل میشوند. دو الگوریتم اصلی در تحلیل پیشگویانه، الگوریتمهای طبقهبندی و رگرسیون هستند. تاکنون ما اصول را توضیح دادهایم، اجازه دهید در ادامه، هر یک را با جزئیات بیشتری بررسی کنیم.
نتیجه سخن
درک کامل پیچیدگیهای رگرسیون و طبقهبندی ممکن است سالها طول بکشد. اما با این مقدمه در پس ذهن خود، شما باید آماده کاوش بیشتر باشید. برای شروع کار خود به عنوان یک تحلیلگر داده، باید دریابید که مدلسازی پیشگویانه چگونه در حوزه گستردهتری از تجزیه و تحلیل دادهها قرار میگیرد.