یادگیری ماشینی (ML) نوعی هوش مصنوعی (AI) است که به برنامههای نرمافزاری اجازه میدهد در پیشبینی نتایج دقیقتر شوند. الگوریتمهای یادگیری ماشین از دادههای تاریخی به عنوان ورودی برای پیشبینی مقادیر جدید خروجی استفاده میکنند.
موتورهای جست و جو از جمله موارد معمول برای استفاده از یادگیری ماشین است. از دیگر موارد معروف میتوان به کشف تقلب، فیلتر کردن هرزنامه، شناسایی تهدیدات بدافزار و اتوماسیون فرآیند کسب و کار (BPA) اشاره کرد.
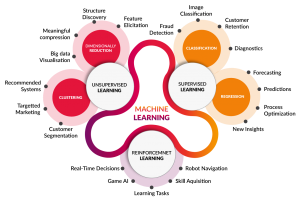
انواع یادگیری ماشین
یادگیری ماشین کلاسیک غالباً بر اساس نحوه یادگیری دقیق تر الگوریتم در پیشبینیها طبقهبندی میشود. چهار رویکرد اساسی وجود دارد: یادگیری تحت نظارت، یادگیری بدون نظارت، یادگیری نیمه نظارت شده و یادگیری تقویت شده. نوع الگوریتمی که کارشناس داده برای استفاده انتخاب میکند به نوع دادهای که میخواهند پیشبینی کنند، بستگی دارد.
یادگیری تحت نظارت
در این نوع یادگیری ماشین، کارشناس داده، الگوریتمهایی را با دادههای آموزشی دارای برچسب تهیه میکند و متغیرهایی را که میخواهند الگوریتم برای همبستگی ارزیابی کند، تعریف میکنند. در این حالت هر دو ورودی و خروجی الگوریتم مشخص شده است.
یادگیری بدون نظارت
این نوع یادگیری ماشین شامل الگوریتمهایی است که روی دادههای بدون برچسب آموزش میبینند. الگوریتم از طریق مجموعه دادهها اسکن میشود و به دنبال هر گونه ارتباط معنیدار است. هم الگوریتمهای داده آموزش میبینند و هم پیش بینیها یا توصیههایی که آنها ارائه میدهند از پیش تعیین شده هستند.
یادگیری نیمه نظارت شده
این رویکرد برای یادگیری ماشین شامل ترکیبی از دو نوع قبلی است. کارشناسان اطلاعات ممکن است الگوریتمی را که غالباً دارای برچسب دادههای آموزشی است تعیین کنند، اما این مدل آزاد است که بتواند دادهها را به تنهایی کشف کند و درک خود را از مجموعه دادهها توسعه دهد.
یادگیری تقویت شده
یادگیری تقویت شده به طور معمول برای آموزش یک ماشین برای تکمیل یک فرآیند چند مرحلهای استفاده میشود که قوانین مشخصی برای آن وجود دارد. کارشناسان، الگوریتمی را برای تکمیل یک کار برنامه ریزی میکنند و هنگام انجام به توجه به چگونگی کار، به آن نشانههای مثبت یا منفی میدهند. اما در بیشتر موارد، الگوریتم به تنهایی تصمیم میگیرد که در این راه چه مراحلی را در بر داشته باشد.
نحوه یادگیری ماشین تحت نظارت
یادگیری ماشین تحت نظارت، کارشناس اطلاعات را ملزم میکند که الگوریتم را هم با ورودیهای برچسب زده شده و هم با خروجیهای دلخواه مد نظر قرار بدهد.
کاربردهای الگوریتم های یادگیری تحت نظارت
- طبقهبندی دوتائی: تقسیم دادهها به دو دسته.
- طبقهبندی چندتائی: انتخاب بین بیش از دو نوع پاسخ.
- مدلسازی رگرسیون: پیشبینی مقادیر مداوم.
- ترکیبی: پیشبینی مدلهای یادگیری ماشین چندگانه برای تولید یک پیشبینی دقیق.
یادگیری ماشین بدون نظارت
الگوریتمهای یادگیری ماشین بدون نظارت نیازی به برچسب گذاری دادهها ندارند. آنها دادههای بدون برچسب را غربال میکنند تا به دنبال الگوهایی باشند که میتواند برای گروهبندی نقاط داده در زیرمجموعهها مورد استفاده قرار گیرد. بیشتر انواع یادگیری عمیق، از جمله شبکههای عصبی و الگوریتمهای بدون نظارت هستند.
کاربردهای الگوریتمهای یادگیری بدون نظارت
- خوشهبندی: تقسیم مجموعه دادهها بر اساس شباهت به گروهها.
- تشخیص ناهنجاری: شناسایی نقاط داده غیرمعمول در یک مجموعه داده.
- استخراج انجمن: شناسایی مجموعه موارد در یک مجموعه داده که غالباً با هم اتفاق میافتند.
- کاهش ابعاد: کاهش تعداد متغیرها در یک مجموعه داده.
یادگیری نیمه نظارت شده
در یادگیری نیمه نظارت شده کارشناسان اطلاعات، مقدار کمی از دادههای آموزشی دارای برچسب را به یک الگوریتم اضافه میکند. از این رو، الگوریتم ابعاد مجموعه داده را میآموزد، سپس میتواند آن را برای دادههای جدید و بدون برچسب اعمال کند. عملکرد الگوریتمها به طور معمول وقتی در مجموعه دادههای دارای برچسب آموزش میبینند، بهبود مییابد. اما برچسب گذاری دادهها میتوانند وقتگیر و گران باشند. یادگیری نیمه نظارت شده بین عملکرد یادگیری تحت نظارت و کارایی یادگیری بدون نظارت، حد وسطی را ایجاد میکند.
مناطقی که از یادگیری نیمه نظارت استفاده میشود
- ترجمه ماشینی: آموزش الگوریتمهای ترجمه زبان بر اساس فرهنگ لغت کامل کلمات.
- تشخیص تقلب: شناسایی موارد کلاهبرداری هنگامی که فقط چند مثال مثبت دارید.
- برچسب گذاری دادهها: الگوریتمهای آموزش داده شده روی مجموعه دادههای کوچک میتوانند یاد بگیرند که به طور خودکار برچسبهای داده را روی مجموعههای بزرگتر بکار ببرند.
یادگیری تقویت شده
یادگیری تقویت شده با برنامهنویسی یک الگوریتم با یک هدف مشخص و مجموعهای از قوانین مقرر برای تحقق این هدف کار میکند. کارشناسان اطلاعات همچنین الگوریتم را برای جستجوی نتیجههای مثبت برنامهریزی میکنند. که وقتی عملی را انجام میدهند برای هدف نهایی مفید باشد و از ضررهای احتمالی اجتناب کنند.
یادگیری تقویت شده و مناطق مورد استفاده
- رباتیک: رباتها میتوانند با استفاده از این روش انجام وظایف را در دنیای فیزیکی یاد بگیرند.
- گیم پلی ویدیویی: برای آموزش رباتها برای انجام تعدادی بازی ویدیویی، از یادگیری تقویت شده استفاده میشود.
- مدیریت منابع: با توجه به منابع محدود و یک هدف مشخص، یادگیری تقویت شده میتواند به شرکتها کمک کند تا بتوانند نحوه تخصیص منابع را برنامهریزی کنند.
موارد استفاده از یادگیری ماشین
امروزه از یادگیری ماشینی در طیف وسیعی از برنامهها استفاده میشود. شاید یکی از مشهورترین نمونههای یادگیری ماشین در عمل، موتور پیشنهادی باشد که ارائه خبررسانی در فیس بوک استفاده میشود.
فیس بوک از یادگیری ماشینی برای شخصیسازی نحوه دریافت اطلاعات هر یک از اعضا استفاده میکند. اگر یک عضو خواندن پستهای یک گروه خاص را به صورت متوالی متوقف کند، موتور توصیه شروع به نشان دادن فعالیت بیشتر آن گروه در اوایل خبرخوان میکند.
در پشت صحنه، موتور در تلاش است الگوهای شناخته شده در رفتار آنلاین عضو را تقویت کند. اگر عضو در هفتههای آینده الگوها را تغییر دهد و نتواند پستهای آن گروه را بخواند، اخبار مطابق با آن تنظیم میشود.
سایر موارد برای یادگیری ماشین
- مدیریت ارتباط با مشتری: نرم افزار CRM میتواند با استفاده از مدلهای یادگیری ماشین، ایمیل را تجزیه و تحلیل کند و اعضای تیم فروش را وادار کند تا ابتدا به مهمترین پیامها پاسخ دهند. سیستمهای پیشرفتهتر حتی میتوانند پاسخهای موثر بالقوه را نیز توصیه کنند.
- هوش تجاری: فروشندگان BI (هوش تجاری) و تجزیه و تحلیل از یادگیری ماشین در نرم افزار خود برای شناسایی نقاط داده بالقوه مهم، الگوهای نقاط داده و ناهنجاریها استفاده میکنند.
- سیستمهای اطلاعاتی منابع انسانی: سیستمهای HRIS میتوانند از مدلهای یادگیری ماشین برای فیلتر کردن برنامهها و شناسایی بهترین نامزدها برای موقعیت باز استفاده کنند.
- اتومبیلهای هوشمند: الگوریتمهای یادگیری ماشین حتی میتوانند یک ماشین نیمه مستقل بتوانند یک جسم قابل مشاهده را تشخیص داده و به راننده هشدار دهند.
- دستیاران مجازی: دستیاران هوشمند معمولاً مدلهای یادگیری ماشین نظارت شده و بدون نظارت را برای تفسیر گفتار طبیعی و زمینه تأمین ترکیب میکنند.

مزایا و معایب یادگیری ماشین
یادگیری ماشینی شاهد موارد استفاده قدرتمندی از پیشبینی رفتار مشتری به عنوان سیستم عامل برای اتومبیلهای هوشمند بوده است. اما فقط به این دلیل که برخی صنایع مزایایی را دیدهاند، به معنای بینقص بودن یادگیری ماشینی نیست.
یادگیری ماشینی میتواند به شرکتها کمک کند مشتریان خود را در سطح عمیقتری درک کنند. با جمع آوری دادههای مشتری و همبستگی آن با رفتارها در طول زمان، الگوریتمهای یادگیری ماشین میتوانند انجمنهایی را بیاموزند و به تیمها کمک کنند ابتکارات توسعه محصول و بازاریابی را متناسب با تقاضای مشتری تنظیم کنند.
برخی از شرکتهای اینترنتی از یادگیری ماشین به عنوان یک عامل اصلی در مدلهای تجاری خود استفاده میکنند. به عنوان مثال Uber از الگوریتمهایی برای تطبیق درایورها با سوارکاران استفاده میکند. Google نیز برای نمایش تبلیغات مناسب در جستجوها از یادگیری ماشینی استفاده میکند.
اما یادگیری ماشینی معایبی نیز دارد. اول و مهمترین، پر هزینه بودن آن است. پروژههای یادگیری ماشین به طور معمول توسط کارشناسان اطلاعات انجام میشود، که هزینههای بالایی را صرف میکنند. این پروژهها همچنین نیاز به زیرساختهای نرم افزاری دارند که میتواند هزینه بالایی داشته باشد.
مشکل دیگر را میتوان تعصب یادگیری ماشین نامید. الگوریتمهایی طراحی میشوند که روی مجموعه دادههایی آموزش دیدهاند تا جمعیت خاصی را حذف کنند یا حاوی خطا هستند و میتوانند منجر به مدلهای نادرستی در جهان شوند. در بهترین حالت، شکست میخورند و در بدترین حالت تبعیض آمیز هستند. هنگامی که یک شرکت فرایندهای اصلی کسب و کار را بر اساس مدلهای مغرضانه قرار میدهد، میتواند با آسیبهای بدون نظارت به اعتبار شهرت برسد.

انتخاب مدل مناسب یادگیری ماشین
روند انتخاب مدل یادگیری ماشینی مناسب برای حل یک مشکل اگر به طور استراتژیک به آن نزدیک نشوید، میتواند وقت گیر باشد.
مرحله ۱: مسئله را با ورودیهای بالقوه دادهای که باید برای راهحل در نظر گرفته شود تراز کنید. این مرحله نیاز به کمک دانشمندان و کارشناسان داده دارد که درک عمیقی از این مسئله دارند.
مرحله ۲: دادهها را جمع آوری کنید، آنها را قالببندی کنید و در صورت لزوم دادهها را برچسب گذاری کنید. این مرحله هم به طور معمول توسط کارشناسان اطلاعات و با کمک دست اندرکاران داده انجام میشود.
مرحله ۳: انتخاب الگوریتم(ها) برای آزمایش و بررسی عملکرد آنها.
مرحله ۴: تنظیم دقیق خروجیها را ادامه دهید تا زمانی که به سطح قابل قبولی از دقت برسند. این مرحله نیز توسط کارشناسان اطلاعات با بازخورد کارشناسانی که درک عمیقی از این مسئله دارند انجام میشود.
اهمیت یادگیری ماشینی قابل تفسیر توسط انسان
وقتی مدل کار پیچیده است، در عین حال میتواند چالش برانگیز هم باشد. در برخی صنایع کارشناسان اطلاعات مجبورند از مدلهای ساده یادگیری ماشین استفاده کنند زیرا توضیح چگونگی تصمیمگیری برای همه ساده نیست اما مهم است. این امر به ویژه در صنایعی که بارهای سنگین انطباق از قبیل بانکداری و بیمه را در بر دارند، صادق است.
مدلهای پیچیده میتوانند پیش بینیهای دقیقی داشته باشند، اما توضیح اینکه یک تعیین کننده برای یک خروجی چه کاری انجام میدهد، همواره دشوار است.
آینده یادگیری ماشین
در حالی که الگوریتمهای یادگیری ماشین برای چندین دهه وجود داشته است، اما با رشد برجسته هوش مصنوعی به محبوبیت جدیدی دست یافتهاند. به ویژه مدلهای یادگیری عمیق، پیشرفتهترین کاربردهای هوش مصنوعی امروزی را تأمین میکنند.
سیستم عاملهای یادگیری ماشین از جمله رقابتیترین حوزههای فناوری سازمانی به حساب میآیند که اکثر فروشندگان عمده از جمله آمازون، گوگل، مایکروسافت، IBM و سایر شرکتها برای ثبت نام مشتریان، خدمات پلت فرم که طیف فعالیتهای یادگیری ماشین را شامل میشود( از جمله جمع آوری دادهها، آماده سازی دادهها، طبقه بندی دادهها، ساخت مدل، آموزش و استقرار برنامهها) مسابقه میدهند.
با افزایش اهمیت یادگیری ماشین برای عملیات تجاری و هوش مصنوعی در تنظیمات سازمانی، جنگهای رقابتی برای یادگیری ماشین تشدید میشود.
تاریخچه یادگیری ماشین
۱۶۴۲ – بلیز پاسکال یک ماشین مکانیکی اختراع میکند که میتواند جمع، تفریق، ضرب و تقسیم کند.
۱۶۷۹ – گوتفرید ویلهلم لایب نیتس سیستم کد باینری را طراحی میکند.
۱۸۳۴ – چارلز بابیج ایده یک دستگاه کلی همه منظوره را که میتواند با کارتهای پانچ شده برنامهریزی شود، طراحی کرد.
۱۸۴۲ – آدا لاولاس دنبالهای از عملیات برای حل مسائل ریاضی را با استفاده از دستگاه کارت پانچ نظری چارلز بابیج توصیف میکند و اولین برنامهنویس نامیده میشود.
۱۸۴۷ – جورج بول منطق بولی را ایجاد کرد، نوعی جبر که در آن میتوان تمام مقادیر را به مقادیر باینری درست یا نادرست تقلیل داد.
۱۹۳۶ – منطق و رمزنگار انگلیسی آلن تورینگ یک ماشین جهانی را پیشنهاد میکند که میتواند مجموعهای از دستورالعملها را رمزگشایی و اجرا کند. دلیل اثباتشده وی اساس علوم کامپیوتر تلقی میشود.
۱۹۵۲ – آرتور ساموئل برنامهای ایجاد کرد تا به کامپیوتر IBM کمک کند تا با بازی بیشتر، در چکرها بهتر عمل کند.
۱۹۵۹ – MADALINE اولین شبکه عصبی مصنوعی است که برای یک مشکل در دنیای واقعی با هدف حذف پژواک از خطوط تلفن، اعمال میشود.
۱۹۸۵ – شبکه عصبی مصنوعی تری Sejnowski و Charles Rosenberg آموزش دیدند که چگونه ۲۰۰۰۰ کلمه را در یک هفته تلفظ کند.
۱۹۹۷ – بازی دیپ بلو از IBM استاد بزرگ شطرنج گری کاسپاروف را شکست داد.
۱۹۹۹ – یک ایستگاه کاری هوشمند نمونه اولیه CAD 22000 ماموگرافی را بررسی کرد و سرطان را ۵۲٪ دقیقتر از رادیولوژیستها تشخیص داد.
۲۰۰۶ – جفری هینتون، اصطلاح یادگیری عمیق را برای توصیف تحقیقات عصبی اختراع کرد.
۲۰۱۲ – یک شبکه عصبی بدون نظارت ایجاد شده توسط Google یاد گرفت گربهها را در فیلمهای YouTube با دقت ۷۴٫۸٪ تشخیص دهد.
۲۰۱۴ – یک چت بات با قبول متقاعد کردن ۳۳٪ از قضات انسانی در مورد آزمایش نوجوان اوکراینی به نام اوژن گوستمن، آزمون تورینگ را پشت سر گذاشت.
۲۰۱۴ – Alpha Go، انسان را در سختترین بازی روی صفحه (Go) در جهان شکست داد.
۲۰۱۶ – LipNet، سیستم هوش مصنوعی DeepMind، کلمات لب خوانی را در ویدئو با دقت ۹۳٫۴٪ تشخیص میدهد.
۲۰۱۹ – آمازون ۷۰ درصد از سهم بازار دستیاران مجازی را در ایالات متحده کنترل میکند.
نتیجه سخن اینکه امروزه تحقیقات مداومی در مورد یادگیری عمیق و هوش مصنوعی به طور فزایندهای در ایجاد برنامههای کاربردی عمومیتر متمرکز است. مدلهای هوش مصنوعی امروزی برای تولید الگوریتمی بسیار بهینه شده برای انجام یک کار، نیاز به آموزش گسترده دارند. اما برخی از محققان در حال کشف روشهایی برای انعطاف پذیری بیشتر مدلها و تکنیکهایی هستند که به ماشین اجازه میدهد متن یاد گرفته شده از یک کار را برای کارهای آینده و البته متفاوت به کار گیرد.
مجموعه
هوش تجاری
- به روز رسانی حاکمیت داده در سازمان: از کجا شروع کنیم
- کارشناس پایگاه داده کیست و چه وظایفی دارد؟
- بررسی تفاوتهای میان داده، اطلاعات و دانش در یک نگاه
- وقتی از هوش تجاری صحبت میکنیم، از چه حرف میزنیم؟
- تبدیل داده به اطلاعات با هوش تجاری
- تجزیه و تحلیل داده (Data Analytics) چیست و چگونه انجام میشود؟
- کلان داده (Big Data) چیست؟
- تجزیه و تحلیل کلان داده (Big Data) چیست و چگونه انجام میشود؟
- مقایسه مفاهیم تحلیل داده، علوم داده و کلان داده (Big Data)
- طراحی پایگاه داده چیست و چگونه انجام میشود؟
- حاکمیت داده (Data Governance) چیست و چه اهمیتی دارد؟
- هوش تجاری (BI) چیست و چه تفاوتی با آنالیز تجاری (BA) دارد؟
- آنچه باید درباره هوش تجاری بدانیم
- هوش تجاری (BI) چطور میتواند به کسب و کار شما کمک کند؟
- معرفی ۵ کتاب برتر درباره هوش تجاری
- ۷ کلید برای یک استراتژی موفقیت آمیز در زمینه هوش تجاری
- ۹ راه عدم موفقیت هوش تجاری
- تجسم داده (Data Visualization) چیست و چرا اهمیت دارد؟
- تمیزسازی داده (Data cleaning) به چه معناست و چه اهمیتی دارد؟
- ۱۰ تکنیک اساسی تجسم داده در ایجاد گزارشهای هوش تجاری
- معرفی ۱۳ روش متداول تجسم دادهها
- تفاوت داشبورد و گزارش چیست؟
- ۱۰ اصل طراحی داشبورد هوش تجاری
- ۱۳ مثال عملی از تحلیل داده با هوش تجاری
- کاربرد هوش تجاری در صنایع مختلف
- معرفی نرم افزارهای مختلف هوش تجاری
- چگونه نرمافزار مناسب هوش تجاری را انتخاب کنیم؟
- پاور بی آی (Power BI) چیست و در هوش تجاری چه کاربردی دارد؟
- راهنمای کامل پاور بی آی (Power BI)
- ویژگیهای نرم افزار Power BI
- تفاوت پاور بی آی و اکسل
- معرفی انواع نمودارها در نرم افزار پاور بی آی (Power BI)
- راهنمای کامل معماری نرم افزار پاور بی آی (Power BI)
- راهنمای انتخاب ابزار مناسب بین پاور بی آی و اکسل
- آموزش توابع زبان DAX در هوش تجاری با پاور بی آی (Power BI)
- معرفی نرمافزار Tableau، کاربردها و محصولات آن
- هر آنچه که لازم است درباره نرمافزار QlikView بدانید
- تفاوت زبان M و DAX در نرم افزار Power BI
- مقایسه ابزار Power BI و Tableau در هوش تجاری
- آموزش Power BI Report Server
- آموزش نصب و راه اندازی Power BI Report Server
- AIOps چیست و چه ساختاری دارد؟
- مسیر شغلی در هوش تجاری
- مهندسی داده چیست؟
- تحلیلگر داده (Data Analyst) کیست و چه کاری انجام میدهد؟
- تحلیلگر هوش تجاری کیست و چگونه میتوان به یک تحلیلگر هوش تجاری تبدیل شد؟
- ۸ مهارت مهم که هر تحلیلگر داده برای موفقیت به آنها نیاز دارد
- معرفی مهمترین مدارک و گواهینامههای مورد نیاز تحلیلگر داده
- آیا داشتن مدرک SQL ضروری است؟ معرفی انواع و اهمیت مدرک SQL
- مهمترین تکنیکهای هوش تجاری
- پیاده سازی هوش تجاری در سازمانها
- نقشه راه پیاده سازی موفق استراتژی هوش تجاری در سازمان
- معرفی ۵ کاربرد ارزشمند هوش تجاری در سازمانها
- داده کاوی چیست و چه تکنیکهایی دارد؟
- همهچیز درباره علم داده و نحوه استفاده از آن
- معرفی معتبرترین مدارک و گواهینامههای علم داده
- معرفی برترین ابزار برای دادهکاوی
- دانشمند داده کیست و چه نقشی در کسب و کار دارد؟
- معرفی برترین زبانهای برنامهنویسی علم داده
- آسان ترین زبان برنامهنویسی برای یادگیری کدام است؟
- تفاوتهای اصلی در نقشهای مهندس داده و دانشمند داده
- زبان برنامهنویسی پایتون چیست و چرا باید آن را یاد بگیرید؟
- یادگیری ماشین چیست؟
- SSRS چیست و چه کاربردی در مدیریت دادهها دارد؟
- SSAS چیست و چه کاربردهایی دارد؟
- بهترین زبانها برای یادگیری ماشین (Machine Learning) کدام هستند؟
- نقشها و مسئولیتهای کلیدی در یک تیم هوش تجاری چیست؟
- تفاوت زبان پایتون (Python) و R در چیست؟
- کاربرد KPI در داشبوردهای هوش تجاری
- زبان برنامه نویسی R چیست؟
- بررسی تفاوتهای میان دادهکاوی و یادگیری ماشین در علم داده
- مروری بر نحوه یادگیری زبان R
- چگونه میتوان یک داشبورد فروش ایجاد کرد؟
- معرفی برترین ابزارهای علم داده
- پایگاه داده چیست و چه اجزایی دارد؟
- انبار داده چیست؟
- مفاهیم، معماری و اجزای انبار داده
- دانشمند داده چه تفاوتی با تحلیلگر داده دارد؟
- فرایند ETL در ایجاد انبار داده چیست؟
- مدلسازی داده چیست؟
- دریاچه داده (Data Lake) چیست و چه ساختاری دارد؟
- بهترین شیوههای طراحی پایگاه داده (Database design)
- نرمالسازی داده چیست و چگونه انجام میشود؟
- سیستمهای پشتیبانی تصمیمگیری چیست و چه کاربردهایی دارد؟
- بازار داده (Data Mart) چیست و چه تفاوتی با انبار داده دارد؟
- تحلیلهای پیشبینی کننده چیست و چگونه انجام میشود؟
- علم تصمیمگیری چیست و چگونه میتوانیم تصمیمات دادهمحور بگیریم؟
- تصمیمگیری مبتنی بر داده چیست و چه تاثیری در موفقیت کسب و کار دارد؟
- کاربرد تحلیل داده در بانکداری و شرکتهای خدمات مالی
- معماری اطلاعات (IA) چیست و چطور میتوان از آن استفاده کرد؟
- کلان داده (Big Data) و بررسی تأثیرات آن بر تجارت الکترونیک
- بانکداری باز (Open Banking) چیست و چه اصولی دارد؟