هوش تجاری
دریاچه داده (Data Lake) چیست و چه ساختاری دارد؟

دریاچه داده (Data Lake) یک مخزن ذخیرهسازی است که میتواند مقدار زیادی از دادههای ساختار یافته، نیمه ساختاری و غیر ساختاری را ذخیره کند. این فضا، مکانی برای ذخیره هر نوع داده در قالب اصلی خود و بدون محدودیت ثابت در اندازه حساب (Account) یا پرونده (File) است. دریاچه داده، مقدار داده در حجم بالایی را برای افزایش عملکرد تحلیلی و یکپارچگی داده ارائه میدهد.
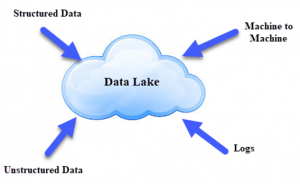
دریاچه داده، مانند ظرف بزرگی است که شباهت زیادی به دریاچه و رودخانههای واقعی دارد. درست مثل اینکه در یک دریاچه چندین شاخه فرعی از رودخانهها وارد میشود، یک دریاچه داده دارای دادههای ساختاری، دادههای غیر ساختاری، ماشین به ماشین (Machine to Machine) و ثبت وقایع پیشآمده در زمان کنونی است.
به بیان دیگر
دریاچه داده، دادهها را دموکراتیک میکند و روشی مقرون بهصرفه برای ذخیرهسازی تمام دادههای یک سازمان برای پردازش بعدی است. تحلیلگر داده میتواند با استفاده از دریاچه داده بر روی یافتن الگوهای معنایی در دادهها و نه خود دادهها متمرکز شود.
برخلاف یک انبار داده (Data Warehouse) سلسلهمراتبی که دادهها در آن در Files و Folder ذخیره میشوند، دریاچه داده، دارای معماری مسطح است. به هر عنصر دادهای در دریاچه داده یک شناسه منحصر به فرد داده میشود و با مجموعهای از اطلاعات فراداده، برچسبگذاری میشود.
چرا دریاچه داده اهمیت دارد؟
هدف اصلی ساخت دریاچه داده، ارائه دید تصفیه نشده دادهها به دانشمندان داده است. دلایل استفاده از دریاچه داده عبارتند از:
- با شروع موتورهای ذخیرهسازی مانند Hadoop، ذخیره اطلاعات متفرقه آسان شده است. با استفاده از دریاچه داده، نیازی به مدلسازی دادهها در یک طرح گسترده در سطح شرکت، نداریم.
- با افزایش حجم داده، کیفیت داده و فراداده، کیفیت تجزیه و تحلیل نیز افزایش مییابد.
- از یادگیری ماشین و هوش مصنوعی میتوان برای پیشبینی سودآور استفاده کرد.
- دریاچه داده یک مزیت رقابتی به سازمان اجرا کننده، ارائه میدهد.
- هیچ ساختار سیلوی دادهای وجود ندارد. دریاچه داده یک دید ۳۶۰ درجه از مشتری به ما میدهد و تجزیه و تحلیل را قویتر میکند.
معماری دریاچه داده به چه صورت است؟
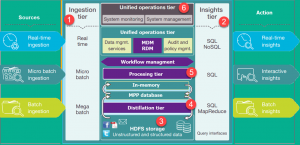
تصویر بالا، معماری دریاچه دادههای یک کسب و کار را نشان میدهد. سطوح پایین نشان دهنده دادههایی است که بیشتر در حالت استراحت هستند در حالی که سطوح بالاتر دادههای معاملاتی در زمان واقعی را نشان میدهند. این دادهها بدون تأخیر یا با کمی تأخیر، از طریق سیستم جریان مییابند. در ادامه طبقات مهم در معماری دریاچه داده را در نظر خواهیم داشت که عبارتند از:
- Ingestion Tier: ردیفهای سمت چپ منابع داده را به تصویر میکشند. دادهها میتوانند به صورت دستهای یا در زمان واقعی در دریاچه داده بارگیری شوند.
- Insights Tier: طبقات سمت راست، نشان دهنده سطح تحقیق است که در آن بینش از سیستم استفاده میشود. برای تجزیه و تحلیل دادهها میتوان از SQL ،NoSQL query یا حتی excel استفاده کرد.
- HDFS: یک راهحل مقرون بهصرفه برای دادههای ساختاریافته و بدون ساختار است. این بخش، یک منطقه فرود (Landing Zone) برای تمام دادههایی است که در سیستم در حالت استراحت هستند.
- Distillation tier: دادهها را از حلقه ذخیرهسازی گرفته و برای تجزیه و تحلیل آسانتر به دادههای ساختاری تبدیل میکند.
- Processing tier: پردازش ردیف الگوریتمهای تحلیلی و پرس و جوهای کاربران با زمان واقعی متفاوت، تعاملی و دستهای برای تولید دادههای ساختار یافته به جهت تجزیه و تحلیل آسانتر.
- Unified operations tier: این ردیف عملیات واحد، حاکم بر مدیریت و نظارت بر سیستم است. این بخش شامل حسابرسی و مدیریت مهارت، مدیریت دادهها، مدیریت گردش کار میباشد.
مفاهیم کلیدی دریاچه
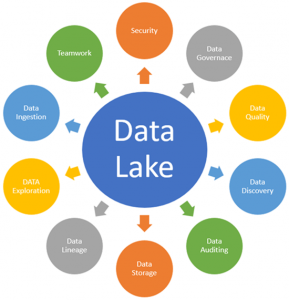
در ادامه مفاهیم کلیدی دریاچه داده آورده شده است که برای درک کامل معماری دریاچه داده، بسیار مهم خواهند بود. این مفاهیم عبارتند از:
Ingestion Data
به اتصالات اجازه میدهد تا دادهها را از منابع مختلف داده دریافت کرده و در دریاچه داده بارگیری کنند. این مفهوم از موارد زیر پشتیبانی میکند:
- انواع دادههای ساختار یافته، نیمه ساختاری و غیر ساختاری.
- استفاده چندین مرتبه از دادهها مانند: مصرف دستهای یا لحظهای.
- انواع مختلفی از منابع داده مانند پایگاه داده، سرورهای وب، ایمیلها، اینترنت اشیا و FTP.
ذخیره اطلاعات
ذخیره داده باید مقیاسپذیر باشد. این مفهوم، ذخیرهسازی مقرون به صرفه را ارائه میدهد و دسترسی سریع به اکتشاف داده را امکانپذیر میکند. این مفهوم باید از قالبهای مختلف داده پشتیبانی کند.
حاکمیت دادهها
حاکمیت دادهها فرآیندی برای کنترل در دسترس بودن، قابلیت استفاده، امنیت و یکپارچگی دادههای مورد استفاده در سازمان است.
امنیت
امنیت باید در هر لایه از دریاچه داده اجرا شود. این کار با ذخیرهسازی، کشف و مصرف شروع میشود. نیاز اساسی این مفهوم، جلوگیری از دسترسی کاربران غیر مجاز است. این ابزار باید از ابزارهای مختلف برای دسترسی آسان به دادهها با GUI و داشبوردها پشتیبانی کند. احراز هویت، حسابداری، مجوز و محافظت از دادهها برخی از ویژگیهای مهم امنیت دریاچه دادهها هستند.
نتیجه سخن
همان طور که گفتیم، دریاچه داده مخزنی برای ذخیرهسازی است که میتواند مقدار زیادی از دادههای ساختار یافته، نیمه ساختاری و غیر ساختاری را ذخیره کند. هدف اصلی ساخت دریاچه داده ارائه دید از دادههای تصفیه نشده به دانشمندان داده است. ردیف عملیات متحد، ردیف پردازش، ردیف تقطیر و HDFS لایههای مهم معماری دریاچه داده هستند.
ترکیب داده، ذخیره داده، کیفیت داده، حسابرسی داده، اکتشاف داده و کشف داده از اجزای مهم معماری داده دریاچه است. طراحی دریاچه داده باید به جای آنچه مورد نیاز است توسط آنچه در دسترس است هدایت شود. از طرف دیگر، این مهم هزینه مالکیت طولانی مدت را کاهش میدهد و امکان ذخیرهسازی پروندهها را فراهم میکند.
در نهایت، بزرگترین ریسک دریاچه دادهها، امنیت و کنترل دسترسی است. گاهی اوقات میتوان دادهها را بدون هیچ نظارتی در دریاچه قرار داد، زیرا برخی از دادهها ممکن است به حریم خصوصی و نظارتی نیاز داشته باشند.
مجموعه
هوش تجاری
- به روز رسانی حاکمیت داده در سازمان: از کجا شروع کنیم
- کارشناس پایگاه داده کیست و چه وظایفی دارد؟
- بررسی تفاوتهای میان داده، اطلاعات و دانش در یک نگاه
- وقتی از هوش تجاری صحبت میکنیم، از چه حرف میزنیم؟
- تبدیل داده به اطلاعات با هوش تجاری
- تجزیه و تحلیل داده (Data Analytics) چیست و چگونه انجام میشود؟
- کلان داده (Big Data) چیست؟
- تجزیه و تحلیل کلان داده (Big Data) چیست و چگونه انجام میشود؟
- مقایسه مفاهیم تحلیل داده، علوم داده و کلان داده (Big Data)
- طراحی پایگاه داده چیست و چگونه انجام میشود؟
- حاکمیت داده (Data Governance) چیست و چه اهمیتی دارد؟
- هوش تجاری (BI) چیست و چه تفاوتی با آنالیز تجاری (BA) دارد؟
- آنچه باید درباره هوش تجاری بدانیم
- هوش تجاری (BI) چطور میتواند به کسب و کار شما کمک کند؟
- معرفی ۵ کتاب برتر درباره هوش تجاری
- ۷ کلید برای یک استراتژی موفقیت آمیز در زمینه هوش تجاری
- ۹ راه عدم موفقیت هوش تجاری
- تجسم داده (Data Visualization) چیست و چرا اهمیت دارد؟
- تمیزسازی داده (Data cleaning) به چه معناست و چه اهمیتی دارد؟
- ۱۰ تکنیک اساسی تجسم داده در ایجاد گزارشهای هوش تجاری
- معرفی ۱۳ روش متداول تجسم دادهها
- تفاوت داشبورد و گزارش چیست؟
- ۱۰ اصل طراحی داشبورد هوش تجاری
- ۱۳ مثال عملی از تحلیل داده با هوش تجاری
- کاربرد هوش تجاری در صنایع مختلف
- معرفی نرم افزارهای مختلف هوش تجاری
- چگونه نرمافزار مناسب هوش تجاری را انتخاب کنیم؟
- پاور بی آی (Power BI) چیست و در هوش تجاری چه کاربردی دارد؟
- راهنمای کامل پاور بی آی (Power BI)
- ویژگیهای نرم افزار Power BI
- تفاوت پاور بی آی و اکسل
- معرفی انواع نمودارها در نرم افزار پاور بی آی (Power BI)
- راهنمای کامل معماری نرم افزار پاور بی آی (Power BI)
- راهنمای انتخاب ابزار مناسب بین پاور بی آی و اکسل
- آموزش توابع زبان DAX در هوش تجاری با پاور بی آی (Power BI)
- معرفی نرمافزار Tableau، کاربردها و محصولات آن
- هر آنچه که لازم است درباره نرمافزار QlikView بدانید
- تفاوت زبان M و DAX در نرم افزار Power BI
- مقایسه ابزار Power BI و Tableau در هوش تجاری
- آموزش Power BI Report Server
- آموزش نصب و راه اندازی Power BI Report Server
- AIOps چیست و چه ساختاری دارد؟
- مسیر شغلی در هوش تجاری
- مهندسی داده چیست؟
- تحلیلگر داده (Data Analyst) کیست و چه کاری انجام میدهد؟
- تحلیلگر هوش تجاری کیست و چگونه میتوان به یک تحلیلگر هوش تجاری تبدیل شد؟
- ۸ مهارت مهم که هر تحلیلگر داده برای موفقیت به آنها نیاز دارد
- معرفی مهمترین مدارک و گواهینامههای مورد نیاز تحلیلگر داده
- آیا داشتن مدرک SQL ضروری است؟ معرفی انواع و اهمیت مدرک SQL
- مهمترین تکنیکهای هوش تجاری
- پیاده سازی هوش تجاری در سازمانها
- نقشه راه پیاده سازی موفق استراتژی هوش تجاری در سازمان
- معرفی ۵ کاربرد ارزشمند هوش تجاری در سازمانها
- داده کاوی چیست و چه تکنیکهایی دارد؟
- همهچیز درباره علم داده و نحوه استفاده از آن
- معرفی معتبرترین مدارک و گواهینامههای علم داده
- معرفی برترین ابزار برای دادهکاوی
- دانشمند داده کیست و چه نقشی در کسب و کار دارد؟
- معرفی برترین زبانهای برنامهنویسی علم داده
- آسان ترین زبان برنامهنویسی برای یادگیری کدام است؟
- تفاوتهای اصلی در نقشهای مهندس داده و دانشمند داده
- زبان برنامهنویسی پایتون چیست و چرا باید آن را یاد بگیرید؟
- یادگیری ماشین چیست؟
- SSRS چیست و چه کاربردی در مدیریت دادهها دارد؟
- SSAS چیست و چه کاربردهایی دارد؟
- بهترین زبانها برای یادگیری ماشین (Machine Learning) کدام هستند؟
- نقشها و مسئولیتهای کلیدی در یک تیم هوش تجاری چیست؟
- تفاوت زبان پایتون (Python) و R در چیست؟
- کاربرد KPI در داشبوردهای هوش تجاری
- زبان برنامه نویسی R چیست؟
- بررسی تفاوتهای میان دادهکاوی و یادگیری ماشین در علم داده
- مروری بر نحوه یادگیری زبان R
- چگونه میتوان یک داشبورد فروش ایجاد کرد؟
- معرفی برترین ابزارهای علم داده
- پایگاه داده چیست و چه اجزایی دارد؟
- انبار داده چیست؟
- مفاهیم، معماری و اجزای انبار داده
- دانشمند داده چه تفاوتی با تحلیلگر داده دارد؟
- فرایند ETL در ایجاد انبار داده چیست؟
- مدلسازی داده چیست؟
- دریاچه داده (Data Lake) چیست و چه ساختاری دارد؟
- بهترین شیوههای طراحی پایگاه داده (Database design)
- نرمالسازی داده چیست و چگونه انجام میشود؟
- سیستمهای پشتیبانی تصمیمگیری چیست و چه کاربردهایی دارد؟
- بازار داده (Data Mart) چیست و چه تفاوتی با انبار داده دارد؟
- تحلیلهای پیشبینی کننده چیست و چگونه انجام میشود؟
- علم تصمیمگیری چیست و چگونه میتوانیم تصمیمات دادهمحور بگیریم؟
- تصمیمگیری مبتنی بر داده چیست و چه تاثیری در موفقیت کسب و کار دارد؟
- کاربرد تحلیل داده در بانکداری و شرکتهای خدمات مالی
- معماری اطلاعات (IA) چیست و چطور میتوان از آن استفاده کرد؟
- کلان داده (Big Data) و بررسی تأثیرات آن بر تجارت الکترونیک
- بانکداری باز (Open Banking) چیست و چه اصولی دارد؟