

هوش تجاری
نرمالسازی داده چیست و چگونه انجام میشود؟

نرمالسازی (Normalization) یک تکنیک طراحی پایگاه داده است که ازدیاد داده را کاهش میدهد و ویژگیهای نامطلوب مانند ناهنجاریهای درج، به روزرسانی و حذف را از بین میبرد. قوانین نرمالسازی جداول بزرگتر را به جداول کوچکتر تقسیم کرده و آنها را با استفاده از روابط بهم پیوند میدهد. هدف از نرمالسازی در SQL حذف دادههای زائد (تکراری) و اطمینان از ذخیره منطقی دادهها است.
مخترع مدل رابطهای (Relational Model) ادگار کاد، تئوری نرمالسازی داده را با معرفی اولین فرم نرمال پیشنهاد داده و همچنان به گسترش نظریه با فرم نرمال دوم و سوم ادامه داد. بعداً او به ریموند اف. بویس پیوست تا نظریه فرم نرمال بویس-کاد را توسعه دهد.
فرمهای نرمال پایگاه داده
در اینجا لیستی از فرمهای نرمال آورده شده است:
- ۱NF (اولین فرم نرمال)
- ۲NF (فرم نرمال دوم)
- ۳NF (فرم نرمال سوم)
- BCNF (فرم نرمال بویس-کاد)
- ۴NF (فرم نرمال چهارم)
- ۵NF (فرم نرمال پنجم)
- ۶NF (فرم نرمال ششم)
نظریه نرمالسازی داده در سرور SQL هنوز در حال توسعه است. به عنوان مثال، حتی در مورد فرم نرمال ششم نیز بحثهایی وجود دارد. با این حال، در اکثر کاربردهای عملی، نرمالسازی در فرم نرمال سوم بهترین نتیجه را مییابد. تکامل نظریههای نرمالسازی SQL در تصویر زیر نشان داده شده است:
![]()
مشکلات عدم نرمالسازی
اگر جدولی به درستی نرمال نشده و افزونگی دادهها را داشته باشد، نه تنها فضای حافظه اضافی را اشغال میسازد بلکه مدیریت و به روزرسانی پایگاه داده را نیز دشوار میکند. در صورت نرمال نبودن پایگاه داده، ناهنجاریهای درج، به روزرسانی و حذف بسیار مکرر است.
ناهنجاری درج (Insertion Anomaly)
فرض کنید در یک جدول داده دانشجو برای پذیرش جدید، تا زمانی که دانشجو شاخهای را انتخاب نکند، داده دانشجو نمیتواند درج شود در غیر این صورت ما باید اطلاعات شاخه را NULL تنظیم کنیم.
همچنین، اگر مجبور شویم دادههای ۱۰۰ دانشجو از همان شاخه را درج کنیم، اطلاعات شاخه برای همه آن ۱۰۰ دانشجو تکرار میشود.
این سناریوها ناهنجاریهای درج هستند.
ناهنجاری بروزرسانی (Updation Anomaly)
اگر آقای X دانشکده را ترک کند چه میشود؟ یا دیگر مدیر گروه علوم کامپیوتر نباشد؟ در این صورت تمام سوابق دانشجویی باید به روز شود و اگر به اشتباه هر رکوردی را از دست بدهیم، منجر به ناسازگاری دادهها میگردد. این ناهنجاری بروزرسانی است.
ناهنجاری حذف (Deletion Anomaly)
در یک جدول دانشجویی، اطلاعات مختلف با هم نگهداری میشوند از جمله اطلاعات دانشجویی و اطلاعات شاخه. از این رو، در پایان سال تحصیلی اگر سوابق دانشجویی حذف شود، ما اطلاعات شاخه را از دست خواهیم داد. این ناهنجاری حذف است.
نرمالسازی پایگاه داده با مثال
با استفاده از مطالعه موردی به راحتی میتوان نمونه نرمالسازی پایگاه داده را درک کرد. فرض کنید یک ویدیو کلوب یک پایگاه داده از فیلمهای اجاره شده را نگهداری میکند. بدون نرمالسازی در پایگاه داده، کلیه اطلاعات در یک جدول مطابق شکل زیر ذخیره میشود. بیایید نرمالسازی در پایگاه داده را با مثال جداول درک کنیم:
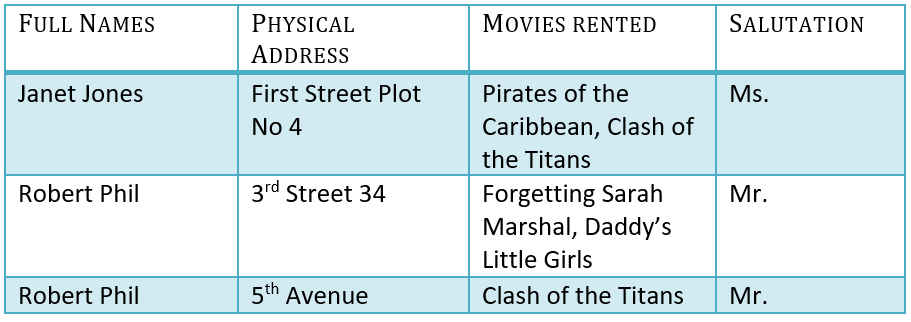
در اینجا میبینید که ستون Movies Rented دارای مقادیر متعددی است. اکنون بیایید اولین فرم نرمال را بررسی کنیم:
قوانین ۱NF (اولین فرم نرمال)
- هر سلول جدول باید دارای یک مقدار واحد باشد.
- هر سابقه باید منحصر به فرد باشد.
جدول فوق در اولین فرم نرمال به شکل زیر است:

قبل از ادامه، بیایید چند چیز را درک کنیم:
کلید (KEY) چیست؟
کلید مقداری است که برای شناسایی سابقه در یک جدول به طور منحصر به فرد استفاده میشود. کلید میتواند یک ستون یا ترکیبی از چند ستون باشد.
نکته: به ستونهای جدول که برای شناسایی منحصر به فرد یک رکورد استفاده نمیشود ، ستونهای غیرکلیدی (non-key) گفته میشود.
کلید اصلی (Primary Key) چیست؟
کلید اصلی یک ستون مقدار است که برای شناسایی رکورد پایگاه داده به طور منحصر به فرد استفاده میشود.
کلید اصلی دارای ویژگیهای زیر است:
- کلید اصلی نمیتواند NULL باشد
- مقدار اصلی باید منحصر به فرد باشد
- مقادیر اصلی اولیه به ندرت باید تغییر کند
- هنگام قرار دادن سابقه جدید باید به کلید اصلی مقدار داده شود
کلید ترکیبی (Composite Key) چیست؟
کلید ترکیبی یک کلید اصلی است که از ترکیب چندین ستون ساخته و برای شناسایی منحصر به فرد یک سابقه استفاده میشود.
در پایگاه داده ما، دو نفر به نام رابرت فیل وجود دارد، اما آنها در مکانهای مختلف زندگی میکنند.

از این رو، ما به نام و نام خانوادگی و آدرس احتیاج داریم تا سابقه را به طور منحصر به فرد شناسایی کنیم. این یک کلید ترکیبی است.
بیایید فرم نرمال دوم را بررسی کنیم.
جمعبندی
- طراحی پایگاه داده برای پیادهسازی موفقیتآمیز یک سیستم مدیریت پایگاه داده که نیازهای دادههای یک سیستم سازمانی را برآورده میکند، حیاتی است.
- فرآیند نرمالسازی در DBMS به تولید سیستمهای پایگاه داده کمک میکند که مقرون به صرفه بوده و دارای مدلهای امنیتی بهتری هستند.
- وابستگیهای عملکردی یکی از مولفههای مهم فرآیند نرمالسازی داده است.
- اکثر سیستمهای پایگاه داده تا فرم نرمال سوم پایگاه داده، نرمال هستند.
- کلید اصلی به طور منحصر به فرد شناسایی میشود در یک جدول ضبط شده و نمیتواند صفر باشد.
- کلید خارجی به اتصال جدول کمک میکند و به کلید اصلی ارجاع میدهد.
مجموعه
هوش تجاری
- به روز رسانی حاکمیت داده در سازمان: از کجا شروع کنیم
- کارشناس پایگاه داده کیست و چه وظایفی دارد؟
- بررسی تفاوتهای میان داده، اطلاعات و دانش در یک نگاه
- وقتی از هوش تجاری صحبت میکنیم، از چه حرف میزنیم؟
- تبدیل داده به اطلاعات با هوش تجاری
- تجزیه و تحلیل داده (Data Analytics) چیست و چگونه انجام میشود؟
- کلان داده (Big Data) چیست؟
- تجزیه و تحلیل کلان داده (Big Data) چیست و چگونه انجام میشود؟
- مقایسه مفاهیم تحلیل داده، علوم داده و کلان داده (Big Data)
- طراحی پایگاه داده چیست و چگونه انجام میشود؟
- حاکمیت داده (Data Governance) چیست و چه اهمیتی دارد؟
- هوش تجاری (BI) چیست و چه تفاوتی با آنالیز تجاری (BA) دارد؟
- آنچه باید درباره هوش تجاری بدانیم
- هوش تجاری (BI) چطور میتواند به کسب و کار شما کمک کند؟
- معرفی ۵ کتاب برتر درباره هوش تجاری
- ۷ کلید برای یک استراتژی موفقیت آمیز در زمینه هوش تجاری
- ۹ راه عدم موفقیت هوش تجاری
- تجسم داده (Data Visualization) چیست و چرا اهمیت دارد؟
- تمیزسازی داده (Data cleaning) به چه معناست و چه اهمیتی دارد؟
- ۱۰ تکنیک اساسی تجسم داده در ایجاد گزارشهای هوش تجاری
- معرفی ۱۳ روش متداول تجسم دادهها
- تفاوت داشبورد و گزارش چیست؟
- ۱۰ اصل طراحی داشبورد هوش تجاری
- ۱۳ مثال عملی از تحلیل داده با هوش تجاری
- کاربرد هوش تجاری در صنایع مختلف
- معرفی نرم افزارهای مختلف هوش تجاری
- چگونه نرمافزار مناسب هوش تجاری را انتخاب کنیم؟
- پاور بی آی (Power BI) چیست و در هوش تجاری چه کاربردی دارد؟
- راهنمای کامل پاور بی آی (Power BI)
- ویژگیهای نرم افزار Power BI
- تفاوت پاور بی آی و اکسل
- معرفی انواع نمودارها در نرم افزار پاور بی آی (Power BI)
- راهنمای کامل معماری نرم افزار پاور بی آی (Power BI)
- راهنمای انتخاب ابزار مناسب بین پاور بی آی و اکسل
- آموزش توابع زبان DAX در هوش تجاری با پاور بی آی (Power BI)
- معرفی نرمافزار Tableau، کاربردها و محصولات آن
- هر آنچه که لازم است درباره نرمافزار QlikView بدانید
- تفاوت زبان M و DAX در نرم افزار Power BI
- مقایسه ابزار Power BI و Tableau در هوش تجاری
- آموزش Power BI Report Server
- آموزش نصب و راه اندازی Power BI Report Server
- AIOps چیست و چه ساختاری دارد؟
- مسیر شغلی در هوش تجاری
- مهندسی داده چیست؟
- تحلیلگر داده (Data Analyst) کیست و چه کاری انجام میدهد؟
- تحلیلگر هوش تجاری کیست و چگونه میتوان به یک تحلیلگر هوش تجاری تبدیل شد؟
- ۸ مهارت مهم که هر تحلیلگر داده برای موفقیت به آنها نیاز دارد
- معرفی مهمترین مدارک و گواهینامههای مورد نیاز تحلیلگر داده
- آیا داشتن مدرک SQL ضروری است؟ معرفی انواع و اهمیت مدرک SQL
- مهمترین تکنیکهای هوش تجاری
- پیاده سازی هوش تجاری در سازمانها
- نقشه راه پیاده سازی موفق استراتژی هوش تجاری در سازمان
- معرفی ۵ کاربرد ارزشمند هوش تجاری در سازمانها
- داده کاوی چیست و چه تکنیکهایی دارد؟
- همهچیز درباره علم داده و نحوه استفاده از آن
- معرفی معتبرترین مدارک و گواهینامههای علم داده
- معرفی برترین ابزار برای دادهکاوی
- دانشمند داده کیست و چه نقشی در کسب و کار دارد؟
- معرفی برترین زبانهای برنامهنویسی علم داده
- آسان ترین زبان برنامهنویسی برای یادگیری کدام است؟
- تفاوتهای اصلی در نقشهای مهندس داده و دانشمند داده
- زبان برنامهنویسی پایتون چیست و چرا باید آن را یاد بگیرید؟
- یادگیری ماشین چیست؟
- SSRS چیست و چه کاربردی در مدیریت دادهها دارد؟
- SSAS چیست و چه کاربردهایی دارد؟
- بهترین زبانها برای یادگیری ماشین (Machine Learning) کدام هستند؟
- نقشها و مسئولیتهای کلیدی در یک تیم هوش تجاری چیست؟
- تفاوت زبان پایتون (Python) و R در چیست؟
- کاربرد KPI در داشبوردهای هوش تجاری
- زبان برنامه نویسی R چیست؟
- بررسی تفاوتهای میان دادهکاوی و یادگیری ماشین در علم داده
- مروری بر نحوه یادگیری زبان R
- چگونه میتوان یک داشبورد فروش ایجاد کرد؟
- معرفی برترین ابزارهای علم داده
- پایگاه داده چیست و چه اجزایی دارد؟
- انبار داده چیست؟
- مفاهیم، معماری و اجزای انبار داده
- دانشمند داده چه تفاوتی با تحلیلگر داده دارد؟
- فرایند ETL در ایجاد انبار داده چیست؟
- مدلسازی داده چیست؟
- دریاچه داده (Data Lake) چیست و چه ساختاری دارد؟
- بهترین شیوههای طراحی پایگاه داده (Database design)
- نرمالسازی داده چیست و چگونه انجام میشود؟
- سیستمهای پشتیبانی تصمیمگیری چیست و چه کاربردهایی دارد؟
- بازار داده (Data Mart) چیست و چه تفاوتی با انبار داده دارد؟
- تحلیلهای پیشبینی کننده چیست و چگونه انجام میشود؟
- علم تصمیمگیری چیست و چگونه میتوانیم تصمیمات دادهمحور بگیریم؟
- تصمیمگیری مبتنی بر داده چیست و چه تاثیری در موفقیت کسب و کار دارد؟
- کاربرد تحلیل داده در بانکداری و شرکتهای خدمات مالی
- معماری اطلاعات (IA) چیست و چطور میتوان از آن استفاده کرد؟
- کلان داده (Big Data) و بررسی تأثیرات آن بر تجارت الکترونیک
- بانکداری باز (Open Banking) چیست و چه اصولی دارد؟








خیلی کاربردی بود. ممنون از مطلبی که منتشر کردید.